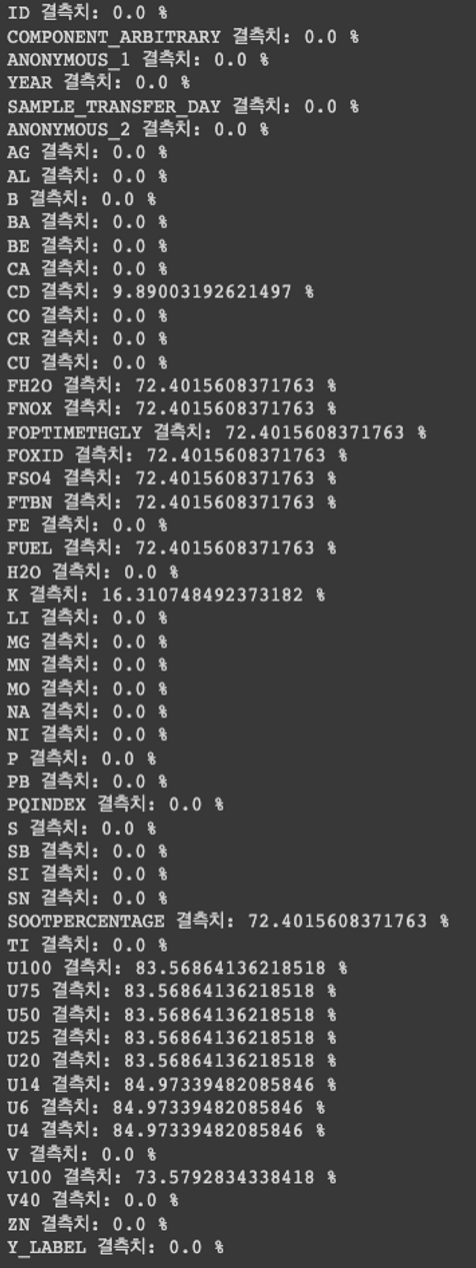
출처: https://www.youtube.com/watch?v=Vhwz228VrIk&list=PLpIPLT0Pf7IoTxTCi2MEQ94MZnHaxrP0j&index=7 안녕하세요! 이전에 신용카드 사기 검출 실습에서 불균형 데이터를 다뤘었는데 불균형 데이터를 처리하는 다른 방법들은 무엇이 있을까 궁금하여 찾아보다 제가 강의를 자주 듣던 김성범 교수님 채널에서 불균형 데이터 분석을 위한 샘플링 기법 강의를 보고 공부하여 포스팅하게 되었습니다. 그럼 불균형 데이터를 처리하는 여러 샘플링 기법들에 대해서 알아보겠습니다. 불균형 데이터란? 1-1. 개념 1-2. 문제점 데이터를 조정해서 불균형 데이터를 해결하는 샘플링 기법들 2-1. 언더 샘플링 2-1-1. Random Sampling 2-1-2. Tome..