DACON 에서 TeamBALAB이 공유한 EDA코드를 바탕으로 EDA를 진행하였다.
train = pd.read_csv('/content/drive/MyDrive/train.csv')
test = pd.read_csv('/content/drive/MyDrive/test.csv')# show dataframe for each features that we have
dataFeatures = []
dataType = []
null = []
nullPCT = []
unique = []
minValue = []
maxValue = []
uniqueSample = []
for item in list(train):
dataFeatures.append(item)
for item in dataFeatures:
dataType.append(train[item].dtype.name)
for item in dataFeatures: # 결측치 갯수
null.append(len(train[train[item].isnull() == True]))
for item in dataFeatures: # 결측치 비율
nullPCT.append(round(len(train[train[item].isnull() == True])/len(train[item])*100,2))
for item in dataFeatures: # 최솟값
minValue.append(train[item].min())
for item in dataFeatures: # 최댓값
maxValue.append(train[item].max())
for item in dataFeatures: # 고윳값의 총 수
unique.append(train[item].nunique())
for item in dataFeatures: # 고윳값 샘플
uniqueSample.append(train[item].unique()[0:2])
train_info = pd.DataFrame({
'dataFeatures' : dataFeatures,
'dataType' : dataType,
'null' : null,
'nullPCT':nullPCT,
'unique' : unique,
'minValue' : minValue,
'maxValue' : maxValue,
'uniqueSample':uniqueSample
})
train_infotrain.csv 파일을 pandas로 load 한 다음에 각각의 feature가 가진 특성(결측치, 최소최대, 고윳값)등을 리스트로 만들어 한 눈에 보기 좋게 정리하였다.

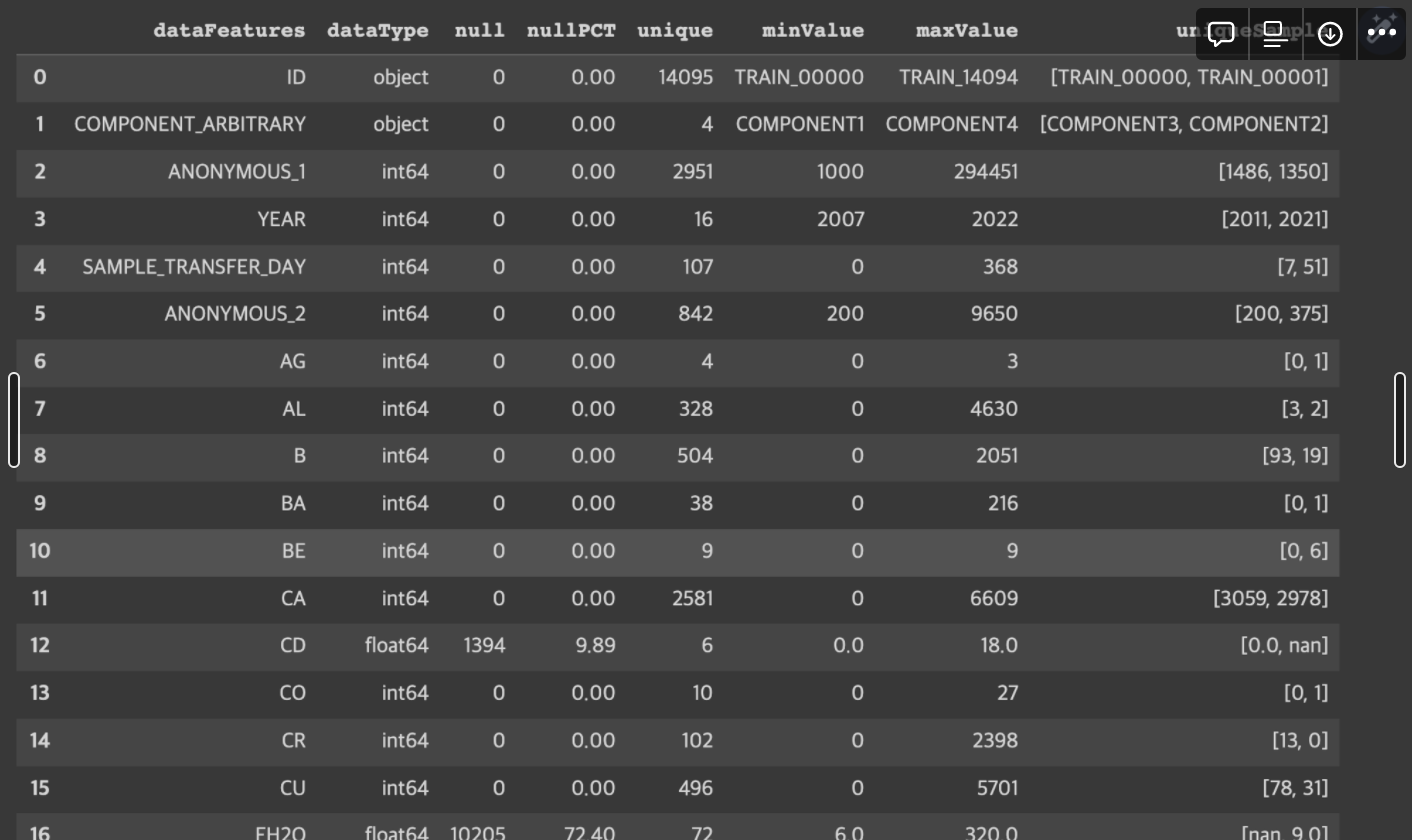
# show dataframe for each features that we have
dataFeatures = []
dataType = []
null = []
nullPCT = []
unique = []
minValue = []
maxValue = []
uniqueSample = []
for item in list(test):
dataFeatures.append(item)
for item in dataFeatures:
dataType.append(test[item].dtype.name)
for item in dataFeatures:
null.append(len(test[test[item].isnull() == True]))
for item in dataFeatures:
nullPCT.append(round(len(test[test[item].isnull() == True])/len(test[item])*100,2))
for item in dataFeatures:
minValue.append(test[item].min())
for item in dataFeatures:
maxValue.append(test[item].max())
for item in dataFeatures:
unique.append(test[item].nunique())
for item in dataFeatures:
uniqueSample.append(test[item].unique()[0:2])
test_info = pd.DataFrame({
'dataFeatures' : dataFeatures,
'dataType' : dataType,
'null' : null,
'nullPCT':nullPCT,
'unique' : unique,
'minValue' : minValue,
'maxValue' : maxValue,
'uniqueSample':uniqueSample
})
test_info

test.csv도 마찬가지로 정리해주었다.
'Project > DACON: 건설기계 오일 상태 분류 AI 경진대회' 카테고리의 다른 글
| Data Processing (2) Feature Scaling (0) | 2023.01.11 |
|---|---|
| Data Processing (1) 결측치 처리 (0) | 2023.01.10 |
| EDA (4) 데이터 시각화 (0) | 2023.01.10 |
| EDA (3) 결측치, 이상치 확인 (0) | 2023.01.10 |
| EDA (1) 도메인 지식, Column 정의 (0) | 2023.01.06 |